Microsoft und Nvidia kooperieren für riesiges AI-Sprach-Modell
12. Oktober 2021 -
Microsoft und Nvidia legen Ressourcen zusammen, um AI-Sprachmodelle zu trainieren und die Herausforderungen um die Verarbeitung von gigantischen Datensätzen für AI-Trainings anzugehen.
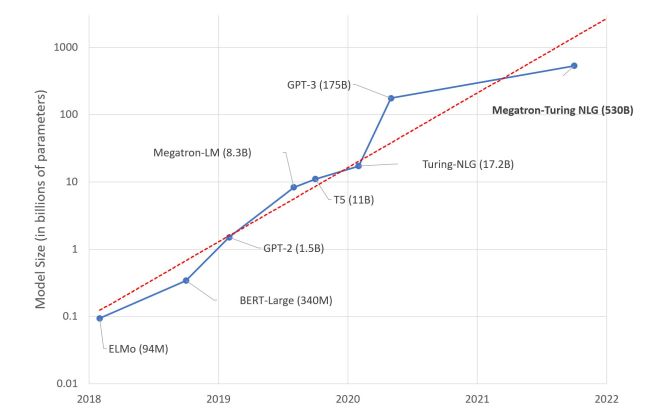
Microsoft und Nvidia haben bekannt gegeben, dass man zusammen an einem Modell zur Erzeugung natürlicher Sprache arbeitet, das alle bisherigen Standards übertrumpfen soll. Das Deepspeed- and Megatron-angetriebene Megatron-Turing Natural Language Generation Model (MT-NLG) ist laut den beiden Unternehmen mit 530 Milliarden Parametern das bis dato grösste Sprachmodell, das jemals trainiert wurde. Die Aufgaben, die MT-NLG verarbeiten kann, umfassen etwa Vorhersagen für Textkomplettierung, Leseverständnis und Schlussfolgerungen in natürlicher Sprache.
Im Rahmen der Zusammenarbeit wollen Microsoft und Nvidia auch weiter an der Optimierung von grossen AI-Modellen arbeiten. Die Probleme von grossen AI-Modellen verorten die beiden Unternehmen im Prinzip in der Machbarkeit: Zum einen sei aktuelle die Hardware nicht in der Lage, alle Parameter für ein solches Modell überhaupt zu verarbeiten oder aber es kommt zu unrealistisch langen Trainingszeiten für die Modelle. Dank Optimierungen, der Kombination der Hardware- und Infrastrukturkompetenzen der beiden Unternehmen, speziellem Software Design und der Modellkonfiguration konnten mit MT-NLG nun erste Erfolge verzeichnet werden.
Detaillierte Erklärungen und Massnahmen für das Training von MT-NLG sind auf dem Microsoft-Blog zu finden. (win)
Im Rahmen der Zusammenarbeit wollen Microsoft und Nvidia auch weiter an der Optimierung von grossen AI-Modellen arbeiten. Die Probleme von grossen AI-Modellen verorten die beiden Unternehmen im Prinzip in der Machbarkeit: Zum einen sei aktuelle die Hardware nicht in der Lage, alle Parameter für ein solches Modell überhaupt zu verarbeiten oder aber es kommt zu unrealistisch langen Trainingszeiten für die Modelle. Dank Optimierungen, der Kombination der Hardware- und Infrastrukturkompetenzen der beiden Unternehmen, speziellem Software Design und der Modellkonfiguration konnten mit MT-NLG nun erste Erfolge verzeichnet werden.
Detaillierte Erklärungen und Massnahmen für das Training von MT-NLG sind auf dem Microsoft-Blog zu finden. (win)
Copyright by Swiss IT Media 2024